リスト (List)と配列 (Array)
多量のデータを保存し使用するための機能
コンピュータの特徴の一つは、高速かつ正確にデータ処理が行えることだ。処理対象のデータが少ない場合には、あっという間に処理が終わるため、コンピュータの特徴を活かすことができない。コンピュータの高速性を活かすためには、高速な処理が必要な大量のデータが必要である。
データを保存する領域としては、変数を利用することができるが、それぞれの変数は基本的には一つのデータしか保存できない。このため、単純に変数をいくつか用意しても、保存できるデータは僅かでしかない。
大量のデータを記録し、高速なコンピュータの処理能力に、大量のデータを供給するデータの保存場所として「配列」と呼ばれるデータ記録機能が用意されている。
配列
配列は、同じ型のデータを連続して格納するためのデータ構造です。各要素は添え字(index)によって一意に識別され、添え字は0から始まります。配列は、メモリ上で連続的な領域を占めるため、高速にランダムアクセス(任意の要素に直接アクセス)することが可能です。
配列の特徴と利点
- データの一括管理:
- 配列を使用することで、複数のデータを一つの変数にまとめて管理できます。例えば、10人分の名前を保存する場合、10個の変数を使う代わりに、1つの配列にまとめることができます。
- 効率的なアクセスと操作:
- 配列は添え字を使って要素に直接アクセスできるため、データの取得や更新が高速に行えます。これにより、検索やソートなどの操作も効率的に行えます。
- 繰り返し処理の簡素化:
- 配列を使うことで、同じ処理を複数のデータに対して一括で行うことができます。例えば、
forループを使って配列の全要素を順番に処理することができます。
- 配列を使うことで、同じ処理を複数のデータに対して一括で行うことができます。例えば、
配列の重要性
- コードの簡潔化:
- 配列を使うことで、同じ種類のデータをまとめて扱えるため、コードが簡潔になります。これにより、可読性が向上し、バグの発生を減らすことができます。
- パフォーマンスの向上:
- 配列はメモリ上で連続的に配置されるため、キャッシュ効率が良く、データのアクセス速度が向上します。特に、大量のデータを扱う場合に効果を発揮します。
- データ構造の基礎:
- 配列は多くの複雑なデータ構造(リスト、スタック、キュー、ツリーなど)の基礎となるため、プログラミングの基本的な概念として重要です。
配列とリスト
本資料では、苦渋の選択としてリストを配列的に使用する場合には、配列ではなく、リスト(配列)と表記して説明する。
情報Ⅰの教科書や、情報工学の専門家ではない投稿者のWeb記事では、Pythonのリストを配列と呼んで誤った説明をしているものが多いが、情報工学・情報科学的あるいは計算機工学的には、配列とリストは全くの別物である。挙句の果てに、リストを配列と呼びながら、配列にはないリストの機能を使ったプログラムを多数掲載している情報Ⅰ教科書も多い。配列とリストが同じものかどうかは、「配列 リスト 違い」などでググってみるとよい。ICT(情報通信技術)教育を推進すると主張し、情報Ⅰとその教科中でプログラミングの教育を行うのであれば、情報工学の正しい用語と知識を教示すべきである。
リストを配列と称してさらにはリストの機能であるデータの追加削除操作を説明するのは、サメをイルカと称して紹介し、さらにはイルカは魚類でエラ呼吸をすると説明しているのと何ら変わらない。
例えば大学や社会で情報工学・科学に深くかかわらないのであれば、目くじらを立てるまでもないかもしれないが、情報工学・科学に関わる可能性があるのであれば、以下の項目を頭に入れて教科書や参考書の記述に注意しておくべきである。
- 配列とリストは全く異なるデータ構造である。
- 配列の要素数は配列の定義あるいは使用開始時に確定し、それ以降は要素の追加削除はできない。
- 要素の追加削除ができるのであればそれはリストである。
Pythonのリストは使いやすく配列と同様な使用法ができる一方で、配列はその基本特性上制約が多いため、特にPythonの入門用の教科書や参考書では、多数のデータを保存するデータ構造を配列と呼んでいても、本当の配列を使用している例はほぼない。
配列とリストの共通特性
- 多数のデータを記録できる。
- データの格納順序が決まっている。
- データはその格納位置を0からの整数値で指定して取り出したり置き換えたりすることができる。
配列の特性
- 配列の要素のデータ型は1種類のみである。
- 使う前もしくは最初に配列に格納できる要素の数を決めなければならず、途中で要素数を変更(増減)することはできない。
- 配列の要素を置き換えることはできるが、要素を追加削除することはできない。
- リストに比べてメモリの使用量が一般的に数分の1、逆に言えば同じメモリ容量であれば、数倍のデータを記録できる。
- リストに比べて、原理的には読み書きの速度が速い。
リストの特性
- Pythonを含め、記録できるデータの型が1種類に限定されないプログラミング言語がある。
- 使う前もしくは最初にリストであることを示さなければならないが、要素数は0も含めて任意で良く、途中で変更(増減)することもできる。
- リストの要素を置き換えることができるし、要素を追加削除することもできる。
リスト(配列)の定義
リスト(配列)の定義は以下のような形式で行う。
- リスト(配列)は要素を読み書きする前に定義しなければならない。
- リスト名 = [要素1, 要素2, ... 要素n]
- 要素はすべて同じデータ型とする(配列の一般的な制限)
- Pythonで配列の代わりに使用されているリストでは、異なるデータ型の要素が混在していても良いが、共通テストで使われる配列ではすべての要素データ型は同一でなければならない。
- リスト名は通常の変数名と同じ形式とする。
- 要素は0個以上で、要素が2個以上の場合には、カンマ [ , ] で列挙する
- Pythonで配列の代わりに使用されているリストでは要素は0個でも良いが、配列では0個要素の配列は意味がない。
リスト(配列)の定義例を以下に示す。1行目は10人の英語の試験の点数(整数値)を要素として持つリスを示す。2行目は10人の身長(実数値)を要素として持つリストを示す。3行目は九州の件名(文字列)を要素として持つリストを示す。4行目は、その要素を参照するための添え字が素数の場合には真、それ以外は偽を要素として持つリストを示す。
eigo = [71, 87, 85, 79, 94, 53, 81, 68, 78, 69]
shintyo = [150.8, 163.8, 176.4, 161.6, 156.4, 177.1, 151.6, 174.3, 176.3, 155.6]
pref_kyushu = ["福岡県", "佐賀県", "長崎県", "熊本県", "大分県", "宮崎県", "鹿児島県"]
sosu = [False, False, True, True, False, True, False, True, False, False]すべてのリスト(配列)は、配列として適切に使用できるように、すべての要素が同じデータ型の要素で構成されている。
3,4行目は要素が使用される前にリスト(配列)が定義されていない例で、プログラムの実行時にエラーとなる。
mylist = [0, 10, 20, 30]
print(mylist[2]) # 普通に20が表示される
print(miteigi[2]) # miteigiが定義されていないのでエラーとなる
miteigi[2] = 10 # これもmiteigiが定義されていないのでエラーとなる上記のプログラムの実行例を以下に示す。以下の出力例では、エラーメッセージは最後の2行のみを示している。4行目がエラーになることを確認するためには、先にエラーとなりプログラムの実行を止めてしまう3行目のプログラムの行頭に#を追加して注釈(コメント)にする必要がある。
20
File "<exec>", line 3, in <module>
NameError: name 'miteigi' is not defined情報教科書等のPythonプログラムで配列として使用されているデータ構造は、実際にはPythonのリストである。Pythonのリストは、異なるデータ要素を混在して含むことができる。その例を以下に示す。
mix = [71, 87, 150.8, 163.8, "福岡県", "佐賀県", False, False, True]
print(mix)[71, 87, 150.8, 163.8, '福岡県', '佐賀県', False, False, True]Pythonのリストでは異なるデータ型の要素が混在したリストが適切に扱われることが確認できる。ただし、このテキストでは異なるデータ型を一つのリストに混在させる上記の様なリストの使用法は基本的に紹介しない。
リスト(配列)
リスト(配列)の使用例として、生徒諸君の試験の成績処理を考えてみよう。
例えば、10人の生徒に対して英語の試験結果を記録した点数表があるとし、その平均点、最高点、最低点などを求めるプログラムの作成を考える。
変数を使用した多数のデータの格納法
処理対象として10個の点数がある場合、その点数をコンピュータに格納して処理をする方法としては、これまでの知識では、10個の変数、例えばeigo1-eigo10の変数を用意して点数を格納し処理をすることが考えられる。この方法では、例えば1000人の生徒の得点を処理したい場合には、1000個の変数を用意しなければならず現実的ではないし、後で確認するが、そのデータに対する処理(プログラム)の記述も大変なことになる。
eigo1 = 71
eigo2 = 87
eigo3 = 85
eigo4 = 79
eigo5 = 94
eigo6 = 53
eigo7 = 81
eigo8 = 68
eigo9 = 78
eigo10 = 69リスト(配列)を使用した多数のデータの格納法
ここでは幸いにして、リスト(配列)という新しいデータの格納法を学んでいるので、リスト(配列)を使用しで英語の点数を記録する方法を考えよう。
配列は同じ特性(すべて整数値とか、すべて文字列とか)の多数のデータを一塊のデータとして定義することができる。
その配列の特性を利用して、10個の英語の点数は以下のように記述することができる。
eigo = [71, 87, 85, 79, 94, 53, 81, 68, 78, 69]リスト(配列)に関する用語とリスト(配列)の使用法を以下に示す。
- リスト(配列)に記録されたデータは、リスト(配列)の要素と呼ばれる。
- リスト(配列)に記録された要素数はリスト(配列)の大きさ・サイズと呼ばれる。
- リスト(配列)の大きさは len() 組み込み関数を使用して取得することができる。
- リスト(配列)の要素は、「リスト名[添え字]」の形式で指定し、そのデータを取り出したり新たな値を代入できる。
- 英語の得点の例では、リスト(配列)の最初の要素は eigo[0] と表現される。
- 添え字は、インデックス (index) とも呼ばれ0以上の整数値が使用される。
- リスト(配列)の最初の要素の添え字は 0 である。
- n個のデータを記録したリストの最後の要素の添え字は n-1 である。
- 例えば、10個のデータを記録したリスト(配列)の最後の添え字は9である。
- n個のデータを記録したリスト(配列)の最後の要素の添え字としてn以上を使用するとエラーになる
リスト(配列)の要素の基本操作
リストの要素を取り出したり更新(代入)したりする方法を確認してみよう。
eigo = [71, 87, 85, 79, 94, 53, 81, 68, 78, 69] # 10個の英語の点数を1つのリストで定義
print(len(eigo)) # リストの大きさ
print(eigo[0]) # 0はリストの最初の要素
print(eigo[5]) # 5はリストの6番目の要素
eigo[9] = 10 # 10番目の要素(69)に10を代入して変更
print(eigo[9]) # 10番目の要素が変更されていることが確認できる
tmp = eigo[3] # 4番目の要素と5番目の要素を交換するために、4番目の要素を一時的に退避
eigo[3] = eigo[4] # 5番目の要素を4番目の要素に代入して更新
eigo[4] = tmp # 5番目の要素に退避しておいた4番目の要素を代入して更新:交換完了
print(eigo) # リスト全体を表示して変更内容も確認できる10
71
53
10
[71, 87, 85, 94, 79, 53, 81, 68, 78, 10]リスト(配列)の大きさ以上の添え字の指定
リスト(配列)の添え字が誤っている場合のプログラムの動作を確認してみよう。
eigo = [71, 87, 85, 79, 94, 53, 81, 68, 78, 69] # 10個の英語の点数を1つのリストで定義
print(eigo[10]) # 配列の大きさは 10以下にプログラムの実行で表示されるエラーメッセージの最後の2行を示す。
File "<exec>", line 2, in <module>
IndexError: list index out of range負の添え字の利用
多くのプログラミング言語では、リスト(配列)の添え字は、前述のように0以上の整数値と定められている。このため、上記の様にリスト(配列)のサイズを超える添え字の指定の時と同様に、-1とか、-12とか、負の整数を指定すると、エラーとして処理されるのが一般的である。
しかしながらPythonは少し気の利いた機能が追加されており、負の添え字を指定した場合には、配列の左端からではなく、右端からの要素数でリスト(配列)の要素を指定できるようになっている。
eigo = [71, 87, 85, 79, 94, 53, 81, 68, 78, 69] # 10個の英語の点数を1つのリストで定義
print(eigo[-1]) # リストの右端の要素
print(eigo[-2]) # リストの右端から2番目の要素
print(eigo[-10]) # 5はリストの6番目の要素69
78
71便利な機能で、Pythonでプログラムを作成する際にはこの機能を有効活用することが多いが、他の多くのプログラミング言語にこの機能がないことには注意する必要がある。少なくとも、共通テストの問題では、この機能を利用した解答を求められることはないし、この機能を利用して解答できたとしても、一般的ではなくDNCLにも規定されていない機能なので、不正解となり点を失う可能性が高い。したがって、受験勉強としてのプログラミングでは、リスト(配列)に対して負の添え字を使う方法は考えるべきではない。
リスト(配列)の利用
平均点の計算
リスト(配列)に格納された英語の得点の平均点を求めるプログラムを作成しよう。
平均点の求め方の手順の代表的なものは以下の通り。
- すべての点数を加算して合計点を求める。
- 合計点を点数の個数で割って平均点を求める。
上記の処理手順の2番目の処理は、簡単に行うことができる。
例えば、合計点が変数totalに求まっているとすると、それを点数の数すなわちリストの大きさ len(リスト)で割ることにより求めることができる。
次に、1番目の処理手順のリスト(配列)に記録されたすべての要素の合計点を求める方法を考えてみよう。
すべての要素を単純に加算
最も基本的な処理方法としては、リスト(配列)のすべての要素を単純に並べて加算する方法だろう。
eigo = [71, 87, 85, 79, 94, 53, 81, 68, 78, 69] # 10個の英語の点数を1つのリストで定義
total = eigo[0]+eigo[1]+eigo[2]+eigo[3]+eigo[4]+eigo[5]+eigo[6]+eigo[7]+eigo[8]+eigo[9]
print("英語の得点データは", eigo)
print("合計値は", total)この方法は単純でわかりやすい方法ではあるが、以下のような問題があり実用的ではない。
- 要素の数だけ要素を並べて加算処理を書かなくてはならない。
- 要素の数が変わったら、加算処理を追加削除しなければならない。(データの数が分かるたびにプログラムを書き換えねばならず、汎用性がなくなる)
合計値の計算を要素ごとの加算処理に分解
コンピュータで多数のデータに対して処理を行うプログラムを作成する際の重要な考え方の一つは、処理したいことを小さな処理単位に分解し、その処理単位の繰り返しや組み合わせで大きなあるいは多数のデータに対する処理を行う方法を考えることだ。
ここでは、リスト(配列)のすべての要素の加算を、すべての要素を一挙に加算するのではなく、一つ一つの要素の段階的な加算に分解して処理を考える。
以下の処理の分解例では、リスト(配列)一つの要素に対して合計値を求めるための加算を行っている処理が5,6行目に書かれており、それと全く同じ処理が以下9個、合計で10個繰り返し書かれる形になっている。この方法では、例えばリストの要素である得点が20個になれば、5,6行目に書かれている処理を単純に20回に増やせば、合計を求められることがわかる。
eigo = [71, 87, 85, 79, 94, 53, 81, 68, 78, 69] # 10個の英語の点数を1つのリストで定義
total = 0
i = 0
total = total + eigo[i]
i = i + 1 # i = 1
total = total + eigo[i]
i = i + 1 # i = 2
total = total + eigo[i]
i = i + 1 # i = 3
total = total + eigo[i]
i = i + 1 # i = 4
total = total + eigo[i]
i = i + 1 # i = 5
total = total + eigo[i]
i = i + 1 # i = 6
total = total + eigo[i]
i = i + 1 # i = 7
total = total + eigo[i]
i = i + 1 # i = 8
total = total + eigo[i]
i = i + 1 # i = 9
total = total + eigo[i]
i = i + 1 # i = 10
print("英語の得点データは", eigo)
print("合計値は", total)英語の得点データは [71, 87, 85, 79, 94, 53, 81, 68, 78, 69]
平均値は 76.5しかしながら、5,6行の処理の記述を要素の増加に合わせて追加しなければならないのであれば、一つ前に示した処理方法と同様な問題が生じる。しかしながら、われわれは、同じ処理を繰り返し書かなくても同じ処理を繰り返し実行する方法を簡潔に記述する方法をすでに学んでいる。
繰り返し文の利用
同じ処理を繰り返し実行したい場合には、while文やfor文を使用することができる。
- 繰り返し処理を使う場合には、先の例では5,6行目の処理を繰り返し実行できるようにすればよい。
- 繰り返しの回数は、リストの大きさを指定すればよい。
繰り返し処理を利用すると、要素数の増減で処理行を増減させる必要はなく、処理回数の増減は、繰り返し回数の増減で制御すればよいことになる。
while文を使用したリスト(配列)の要素の繰り返し処理
while文を使用してリスト(配列)に記録された英語の得点の平均値を求めるプログラムを以下に示す。
このプログラムでは、リスト(配列)の要素を指定する添え字として使用される変数の名前をiとしている。添え字の名前として、i, j, kなどが多用されるので、特に理由がない場合には、配列の添え字として使用する変数名には i, j, kなどを使用すると良い。以下のような文字の意味や歴史的な経緯から、i, j, k等の変数が使用されたプログラムを見た場合には、リスト(配列)の添え字に使用されるのではないかと想定するソフトウェアエンジニアは多い。
- iは添え字(インデックス:index)の頭文字である。
- i, j, k は配列を使用した数値計算に多用されたFortran言語において、無宣言で使用できる整数型の変数名として定められており、奥の数値計算プログラムで配列の添え字を示す変数名として利用されてきた。
eigo = [71, 87, 85, 79, 94, 53, 81, 68, 78, 69] # 10個の英語の点数を1つのリストで定義
total = 0 # 計算を行う前の合計値は 0
i = 0 # リストの最初の要素の添え字
while i < len(eigo): # iがlen(eigo)この場合には10未満の間次の式を繰り返し実行する
total = total + eigo[i] # 現在までの仮の合計値に新たな要素を加算して仮の合計値を更新する
i = i + 1 # 次の要素を使用するために添え字を更新
heikin = total / len(eigo) # 合計値を要素数で割ると平均値が求まる
print("英語の得点データは", eigo)
print("平均値は", heikin)英語の得点データは [71, 87, 85, 79, 94, 53, 81, 68, 78, 69]
平均値は 76.5繰り返し文を利用することにより、得点の増減にも柔軟に対応できるプログラムを作成できたことを確認しよう。
英語の得点リストを以下の30個のデータに置き換えてプログラムを実行してみよう。
eigo = [60, 92, 76, 67, 85, 65, 91, 58, 56, 86, 98, 61, 75, 84, 97, 55, 59, 74, 59, 96, 68, 61, 81, 81, 66, 100, 100, 78, 69, 76]英語の得点リスト(配列)を差し替えるだけで、プログラムを一切書き換えなくても、与えられた30個の得点を処理して平均値を求めることができる汎用性の高いプログラムになっていることを確認できる。
英語の得点データは [60, 92, 76, 67, 85, 65, 91, 58, 56, 86, 98, 61, 75, 84, 97, 55, 59, 74, 59, 96, 68, 61, 81, 81, 66, 100, 100, 78, 69, 76]
平均値は 75.8このように、リスト(配列)と繰り返し処理を組み合わせてプログラムを作成すると、汎用性の高い強力なプログラムを簡単に記述できることが確認できる。
- リスト(配列)の利用により、大量のデータを格納し処理できるようになる。
- 繰り返し処理の利用により、大量のデータに対する処理を少ない行数で書けるとともに、データ数の増減に柔軟に対応できるようになる。
リスト(配列)に対して行うwhile文を使用して記述された繰り返し処理は、for文で簡単に書き換えることができる。
for文を使用したリスト(配列)の要素の繰り返し処理
for文を使用してリスト(配列)に記録された英語の得点の平均値を求めるプログラムを以下に示す。
for文を使用する場合には、iをfor文の制御変数として使用することにより、for文によって、iの値は、繰り返し処理の度に、初期値の0から9まで1づつ増加しながら処理が行われる。
eigo = [71, 87, 85, 79, 94, 53, 81, 68, 78, 69] # 10個の英語の点数を1つのリストで定義
total = 0 # 計算を行う前の合計値は 0
for i in range(len(eigo)): # iを0,1,2,..,8,9と変化させながら次の式を繰り返し実行する
total = total + eigo[i] # 現在までの仮の合計値に新たな要素を加算して仮の合計値を更新する
heikin = total / len(eigo) # 合計値を要素数で割ると平均値が求まる
print("英語の得点データは", eigo)
print("平均値は", heikin)最大値の取得
次に、英語の最高得点を求めるプログラムを作成してみましょう。
最高得点を求める場合も、合計点を求めるのと同様に、リスト(配列)の一つ一つの要素に対する処理に分解し、その処理をすべての要素に対して実行することによって実現します。
- リストの最初の要素を最大値の候補としてnmaxに代入する
- リストの2番目以降の要素に対して以下の処理を繰り返す
- 注目している要素が最大値の候補nmaxより大きいか比較し
- 大きい場合には、最大値の候補としてnmaxに代入し、最大値の候補を更新する
- 注目している要素が最大値の候補nmaxより大きいか比較し
while文を使用してリスト(配列)に記録された英語の得点の最大値を求めるプログラムを以下に示す。
eigo = [71, 87, 85, 79, 94, 53, 81, 68, 78, 69] # 10個の英語の点数を1つのリストで定義
nmax = eigo[0] # リストの最初の要素を最大値の候補とする
i = 1
while i < len(eigo): # iを1,2,..,8,9と変化させながら次の条件処理を繰り返し実行する
if eigo[i] > nmax: # 現在対象となっている得点が最大値の候補よりも大きいならば
nmax = eigo[i] # 最大値の候補を現在の得点で更新する
i = i + 1 # リストの次の要素を対象とするために添え字を更新
print("英語の得点データは", eigo)
print("最大値は", nmax)英語の得点データは [71, 87, 85, 79, 94, 53, 81, 68, 78, 69]
最大値は 94for文を使用してリスト(配列)に記録された英語の得点の最大値を求めるプログラムを以下に示す。
eigo = [71, 87, 85, 79, 94, 53, 81, 68, 78, 69] # 10個の英語の点数を1つのリストで定義
nmax = eigo[0]
for i in range(1, len(eigo)): # リストの0要素は前の行で最大値の候補値として使用されているので、iは1からに変更
if eigo[i] > nmax:
nmax = eigo[i]
print("英語の得点データは", eigo)
print("最大値は", nmax)英語の得点データは [71, 87, 85, 79, 94, 53, 81, 68, 78, 69]
最大値は 94複数のリスト(配列)の連携処理
これまでリスト(配列)を多数ではあるが1種類のデータを格納して使用する用途で使用する例を見てきた。ここでは、関連する複数のリスト(配列)を組み合わせて使用する方法を見ていこう。
以下に、関連する複数のリスト(配列)の例を示す。
成績データの例
以下に、10人の生徒の姓、英語の得点、数学の得点の3つの関連リストの例を示す。
name = ["佐藤", "鈴木", "高橋", "田中", "伊藤", "渡辺", "山本", "中村", "小林", "加藤"]
eigo = [71, 87, 85, 79, 94, 53, 81, 68, 78, 69]
sugaku = [74, 63, 89, 61, 91, 100, 68, 51, 75, 85]それぞれリストの大きさは10で、各リストの同一の添え字で読み書きできるデータは、同一生徒のデータとなるように構成されている。
例えばこのようなリストを使用すると、以下のような生徒ごとの教科別の得点と合計点を示すプログラムを簡単に書くことができる。
name = ["佐藤", "鈴木", "高橋", "田中", "伊藤", "渡辺", "山本", "中村", "小林", "加藤"]
eigo = [71, 87, 85, 79, 94, 53, 81, 68, 78, 69]
sugaku = [74, 63, 89, 61, 91, 100, 68, 51, 75, 85]
print("名前, 英語, 数学, 合計")
for i in range(1, len(name)):
print(name[i], eigo[i], sugaku[i], eigo[i]+sugaku[i])名前, 英語, 数学, 合計
鈴木 87 63 150
高橋 85 89 174
田中 79 61 140
伊藤 94 91 185
渡辺 53 100 153
山本 81 68 149
中村 68 51 119
小林 78 75 153
加藤 69 85 1547行目でprint()関数の出力形式を少し整えると以下の様な出力が得られる。
name = ["佐藤", "鈴木", "高橋", "田中", "伊藤", "渡辺", "山本", "中村", "小林", "加藤"]
eigo = [71, 87, 85, 79, 94, 53, 81, 68, 78, 69]
sugaku = [74, 63, 89, 61, 91, 100, 68, 51, 75, 85]
print("名前, 英語, 数学, 合計")
for i in range(1, len(name)):
print(f'{name[i]:3s}{eigo[i]:6d}{sugaku[i]:6d}{eigo[i]+sugaku[i]:6d}')名前, 英語, 数学, 合計
鈴木 87 63 150
高橋 85 89 174
田中 79 61 140
伊藤 94 91 185
渡辺 53 100 153
山本 81 68 149
中村 68 51 119
小林 78 75 153
加藤 69 85 154この成績情報のリスト(配列)を使用して、英語と数学の平均点が80点以上の生徒の成績を表示するプログラムを作成してみよう。
平均点が80点以上と言っていますが、平均点を求める必要はありません。2教科の平均点が80点以上ということは、2教科の合計点が160点以上の学生の情報を表示すればよいことになります。
name = ["佐藤", "鈴木", "高橋", "田中", "伊藤", "渡辺", "山本", "中村", "小林", "加藤"]
eigo = [71, 87, 85, 79, 94, 53, 81, 68, 78, 69]
sugaku = [74, 63, 89, 61, 91, 100, 68, 51, 75, 85]
print("名前, 英語, 数学, 合計")
for i in range(1, len(name)):
total = eigo[i] + sugaku[i] # 合計点を計算する
if total >= 160: # 合計点が160点以上ならば出力
print(f'{name[i]:3s}{eigo[i]:6d}{sugaku[i]:6d}{total:6d}')名前, 英語, 数学, 合計
高橋 85 89 174
伊藤 94 91 185英語の得点が最高の学生の成績を表示するプログラムを作成してみましょう。プログラムを簡単にするために、英語の最高点を取っている生徒は1名のみと仮定します。
最高点を求めるプログラムはすでに作成しましたが、今回は、最高点を取った生徒の名前や数学の点数なども出力する必要があるので、少し処理方法を考える必要があります。
文字の出力だけでは少し飽きてきたので、成績をグラフ化する方法を試してみましょう。
現在のPyTermでは、グラフ出力に日本語を表示できないので、生徒の名前をローマ字表記に変えています。
import matplotlib.pyplot as plt
name = ["Sato", "Suzuki", "Takahashi", "Tanaka", "Ito", "Watanabe", "Yamamoto", "Nakamura", "Kobayashi", "Kato"]
eigo = [71, 87, 85, 79, 94, 53, 81, 68, 78, 69]
sugaku = [74, 63, 89, 61, 91, 100, 68, 51, 75, 85]
# プロットの作成
plt.clf()
plt.plot(name, eigo, label='eigo', marker='o')
plt.plot(name, sugaku, label='sugaku', marker='x')
plt.title('Seiseki') # タイトルを英語に設定
plt.xlabel('Student') # x軸のラベル
plt.ylabel('Score') # y軸のラベル
plt.grid(True) # グリッドの表示
plt.xticks(rotation=20)
ax=plt.subplot()
ax.set_ylim(0, 100)
ax.legend()
plt.show() # グラフの表示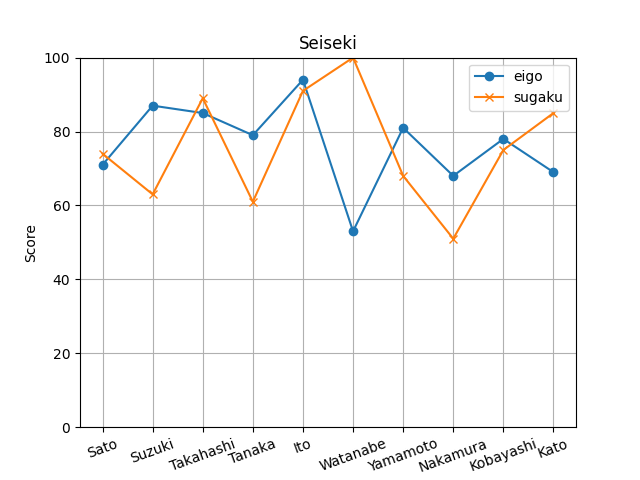
都道府県データの例
# 都道府県名の文字列のリスト(配列)
prefectures = ["福岡県", "佐賀県", "長崎県", "熊本県", "大分県", "宮崎県", "鹿児島県"]
# 都道府県の人口の整数リスト(配列)
prefectures_population = [5135214, 794385, 1266334, 1738301, 1096235, 1041150, 1588256]
# 都道府県の面積の実数リスト(配列)
prefectures_area = [4987.64, 2440.67, 4130.99, 7409.12, 6340.70, 7734.24, 9186.33]配列の制約に対する対処
配列は実行時にその大きさを変更することはできない。
格納するデータ数があらかじめわからない場合には、大きめの配列を確保し、配列の最初の部分からデータを順番に格納していく。実際にデータが記録されている範囲を示す変数を使用して、配列の仕様部分とみ仕様部分を識別する。
基本演習
リストに格納されたデータ群の合計
人口データが正しいか簡単に検証してみましょう。
現在の日本の人口は1億2千万人程度と言われています。上記の都道府県別の人口のリストの合計値が1億2千万程度であれば、正しい可能性が高いと判断しましょう。そのための総人口を求めるプログラムを作成してみましょう。
まずは各自で考えてみましょう。
日本の総人口を求める処理手順
- 合計値totalを0に初期化する
- 都道府県の人口リストのすべての要素に対して以下の処理を繰り返す
- 合計値totalにリストの要素の値を加える
- 合計値totalを表示する
処理手順
- 合計値totalを0に初期化する
- リストのすべての要素に対して以下の処理を繰り返す
- 合計値totalにリストの要素の値を加える
- 合計値totalを表示する
for文でのプログラム例
num_list = [6,4,2,3,8,5,0]
total = 0
for i in range(0, len(num_list)):
total = total + num_list[i]
print('合計値は', total)合計値は 28prefectures_population = [ # 都道府県の人口の整数リスト(配列)
5224614, 1184531, 1163024, 2301996, 913556, 1026228, 1833152,
2867009, 1933146, 1939110, 7344765, 6284480, 14047594, 9237337,
2201272, 1006367, 1109574, 744568, 795544, 2048011, 1978742,
3633202, 7542415, 1770254, 1413610, 2578087, 8837685, 5465002,
1295681, 891620, 537318, 649235, 1888432, 2799702, 1342059,
694841, 925408, 1291198, 666293, 5135214, 794385, 1266334,
1738301, 1096235, 1041150, 1588256, 1467480
]
population = 0
for i in range(len(prefectures_population)):
population = population + prefectures_population[i]
print('総人口', population)総人口 125534017while文でのプログラム例
num_list = [6,4,2,3,8,5,0]
total = 0
i = 0
while i < len(num_list):
total = total + num_list[i]
i = i + 1
print('合計値は', total)合計値は 28prefectures_population = [ # 都道府県の人口の整数リスト(配列)
5224614, 1184531, 1163024, 2301996, 913556, 1026228, 1833152,
2867009, 1933146, 1939110, 7344765, 6284480, 14047594, 9237337,
2201272, 1006367, 1109574, 744568, 795544, 2048011, 1978742,
3633202, 7542415, 1770254, 1413610, 2578087, 8837685, 5465002,
1295681, 891620, 537318, 649235, 1888432, 2799702, 1342059,
694841, 925408, 1291198, 666293, 5135214, 794385, 1266334,
1738301, 1096235, 1041150, 1588256, 1467480
]
population = 0
i = 0
while i < len(prefectures_population):
population = population + prefectures_population[i]
i = i + 1
print('総人口', population)総人口 125534017prefectures_population = [ # 都道府県の人口の整数リスト(配列)
5224614, 1184531, 1163024, 2301996, 913556, 1026228, 1833152,
2867009, 1933146, 1939110, 7344765, 6284480, 14047594, 9237337,
2201272, 1006367, 1109574, 744568, 795544, 2048011, 1978742,
3633202, 7542415, 1770254, 1413610, 2578087, 8837685, 5465002,
1295681, 891620, 537318, 649235, 1888432, 2799702, 1342059,
694841, 925408, 1291198, 666293, 5135214, 794385, 1266334,
1738301, 1096235, 1041150, 1588256, 1467480
]
max_population = prefectures_population[0]
for i in range(1, len(prefectures_population)):
if prefectures_population[i] > max_population:
max_population = prefectures_population[i]
print('最大の人口は', max_population)都道府県の最大人口は 14047594whileを用いた書き換え
複数リストの連携
都道府県名と人口
prefectures = [ # 都道府県名の文字列のリスト(配列)
"北海道", "青森県", "岩手県", "宮城県", "秋田県", "山形県", "福島県",
"茨城県", "栃木県", "群馬県", "埼玉県", "千葉県", "東京都", "神奈川県",
"新潟県", "富山県", "石川県", "福井県", "山梨県", "長野県", "岐阜県",
"静岡県", "愛知県", "三重県", "滋賀県", "京都府", "大阪府", "兵庫県",
"奈良県", "和歌山県", "鳥取県", "島根県", "岡山県", "広島県", "山口県",
"徳島県", "香川県", "愛媛県", "高知県", "福岡県", "佐賀県", "長崎県",
"熊本県", "大分県", "宮崎県", "鹿児島県", "沖縄県"
]
prefectures_population = [ # 都道府県の人口の整数リスト(配列)
5224614, 1184531, 1163024, 2301996, 913556, 1026228, 1833152,
2867009, 1933146, 1939110, 7344765, 6284480, 14047594, 9237337,
2201272, 1006367, 1109574, 744568, 795544, 2048011, 1978742,
3633202, 7542415, 1770254, 1413610, 2578087, 8837685, 5465002,
1295681, 891620, 537318, 649235, 1888432, 2799702, 1342059,
694841, 925408, 1291198, 666293, 5135214, 794385, 1266334,
1738301, 1096235, 1041150, 1588256, 1467480
]
for i in range(len(prefectures)):
print(prefectures[i], prefectures_population[i])北海道 5224614
青森県 1184531
岩手県 1163024
:
:
宮崎県 1041150
鹿児島県 1588256
沖縄県 1467480発展課題
すべての都道府県の名前、自治体番号、人口、面積の4つのリスト(配列)を作ってみましょう。同じ都道府県の情報は、リスト(配列)の同じ位置に置くようにしましょう。
リストの作成には、調査や整理にそれなりに時間がかかると思いますので、作成したリストを以下に示します。
prefectures = [ # 都道府県名の文字列のリスト(配列)
"北海道", "青森県", "岩手県", "宮城県", "秋田県", "山形県", "福島県",
"茨城県", "栃木県", "群馬県", "埼玉県", "千葉県", "東京都", "神奈川県",
"新潟県", "富山県", "石川県", "福井県", "山梨県", "長野県", "岐阜県",
"静岡県", "愛知県", "三重県", "滋賀県", "京都府", "大阪府", "兵庫県",
"奈良県", "和歌山県", "鳥取県", "島根県", "岡山県", "広島県", "山口県",
"徳島県", "香川県", "愛媛県", "高知県", "福岡県", "佐賀県", "長崎県",
"熊本県", "大分県", "宮崎県", "鹿児島県", "沖縄県"
]
"""
prefecture_codes = [ # 都道府県の自治体コードの文字列のリスト
"01", "02", "03", "04", "05", "06", "07",
"08", "09", "10", "11", "12", "13", "14",
"15", "16", "17", "18", "19", "20", "21",
"22", "23", "24", "25", "26", "27", "28",
"29", "30", "31", "32", "33", "34", "35",
"36", "37", "38", "39", "40", "41", "42",
"43", "44", "45", "46", "47"
]
"""
prefecture_codes = [ # 都道府県の自治体コードの作り直してもらった整数のリスト
1, 2, 3, 4, 5, 6, 7,
8, 9, 10, 11, 12, 13, 14,
15, 16, 17, 18, 19, 20, 21,
22, 23, 24, 25, 26, 27, 28,
29, 30, 31, 32, 33, 34, 35,
36, 37, 38, 39, 40, 41, 42,
43, 44, 45, 46, 47
]
prefectures_population = [ # 都道府県の人口の整数リスト(配列)
5224614, 1184531, 1163024, 2301996, 913556, 1026228, 1833152,
2867009, 1933146, 1939110, 7344765, 6284480, 14047594, 9237337,
2201272, 1006367, 1109574, 744568, 795544, 2048011, 1978742,
3633202, 7542415, 1770254, 1413610, 2578087, 8837685, 5465002,
1295681, 891620, 537318, 649235, 1888432, 2799702, 1342059,
694841, 925408, 1291198, 666293, 5135214, 794385, 1266334,
1738301, 1096235, 1041150, 1588256, 1467480
]
# 提供した人口データは、2023年10月1日現在の推計人口に基づいています。
# 2023年10月1日現在の日本の推計人口は、約 1億2435万2000人 です。
prefectures_area = [ # 都道府県の面積の実数リスト(配列)
83423.87, 9645.95, 15275.01, 7282.29, 11637.52, 9323.15, 13784.14,
6097.54, 6408.09, 6362.28, 3797.75, 5156.74, 2194.05, 2416.32,
12583.96, 4247.54, 4186.23, 4190.58, 4465.27, 13561.56, 10621.29,
7777.02, 5173.23, 5774.48, 4017.38, 4612.20, 1905.34, 8400.94,
3690.94, 4724.68, 3507.13, 6707.86, 7114.77, 8479.23, 6112.50,
4146.99, 1876.91, 5675.98, 7102.91, 4987.64, 2440.67, 4130.99,
7409.12, 6340.70, 7734.24, 9186.33, 2282.15
]
# 作成した面積リストの単位は「平方キロメートル(km²)」です。各都道府県の面積を平方キロメートルで表しています。
# 日本の国土面積は、約 37.8万平方キロメートル です。このリストを皆さんが作ろうとするとどのぐらいの時間がかかるでしょうか?
私はとても面倒に感じて手軽に作成したかったので、最新の技術を活用してリスト(配列)を作成しました。
すると、なんと3分ぐらいで上記のリストを作成する(してもらう)ことができました。
Microsoft のCopilotに以下の質問を順番に行った結果が、上記のリスト(配列)と、コメントとして記載した回答です。
- 都道府県名を自治体番号順に並べたPythonリストを作って
- この順番に対応させて各都道府県の自治体番号リストを作って
- 自治体コードのリストのデータを整数値に変更して
- このリストの順番に対応させて、都道府県の人口リストを作って
- 人口は何年のデータですか?
- 2023年10月1日現在の日本の推計人口は?
- 同じ順番で各都道府県の面積のリストを作って
- 作成してくれた面積リストの単位は?
- 日本の国土面積は?
人口や面積の信ぴょう性は改めて確認しなければなりませんが、それぞれのリストで、都道府県の順番を考慮しながら、抜けなくデータを書くだけでも大変です。それ以上に、そもそもいくつかの資料を確認してデータを整理するのはかなり大変です。ところが、このような作業がほんの数分で行えるようになったことは驚きです。効率よく勉強、仕事をめるために有効に活用したいですね。
配列の使用法としての正しさ
上記の都道府県のデータが、配列として正しく作成されているかどうか確認して見ましょう。
- 一つの配列のすべての要素は、一種類のデータ型でなくてはならない
- 一つの配列すべての要素は、一種類の概念に関するデータであるべきである